Resumen Ejecutivo
- La inteligencia artificial es la carga de trabajo de cómputo de más rápido crecimiento, y está creciendo en complejidad, requiriendo cada vez más computación, potencia y ancho de banda.
- También estamos en un punto de inflexión: la IA se está moviendo más allá del centro de datos, y a medida que avanzamos hacia la era de producción de la IA, está claro que su futuro está en la naturaleza.
- La proliferación de la IA desde la nube hasta el cliente y el edge requiere un enfoque holístico que Intel esté equipado de manera única para proporcionar.
- La estrategia de IA de Intel es acelerar la adopción al reducir la barrera de entrada para los clientes. Al aprovechar el éxito de Intel® Xeon® y la sólida cartera de arquitecturas de Intel y adoptar un ecosistema de software abierto, podremos no solo liderar en IA, sino también influir en las tendencias más amplias de la industria para hacer que la IA sea más accesible para todos.
Por Sandra Rivera
Vicepresidente Ejecutivo y Gerente General del Grupo de Centros de Datos e IA
En esencia, la inteligencia artificial (IA) es la capacidad de las máquinas para reconocer patrones y hacer predicciones precisas basadas en ellos. Los modelos de IA continúan volviéndose más sofisticados y complejos, y cada vez requieren más computación, memoria, ancho de banda y potencia.
La IA es la carga de trabajo de cómputo de más rápido crecimiento y uno de los cuatro superpoderes que Intel cree que tendrá un impacto transformador en el mundo. Aunque nació en el centro de datos, creo que el futuro de la IA está en la naturaleza. La era de producción de la IA en el cliente y en el edge finalmente está aquí, y para que la IA prolifere de la nube al edge, la comunidad necesita un enfoque más abierto y holístico para acelerar y simplificar toda la canalización de datos, modelado e implementación. Nuestra estrategia es repetir lo que hemos hecho para otras transiciones tecnológicas importantes a lo largo de nuestra historia: abrirlo a más clientes, acelerar la democratización de la IA y acelerar una adopción más amplia.
Lea más:Semiconductors Run the World (Editorial de Pat Gelsinger) | Ventaja de software de Intel, decodificada (Greg Lavender Editorial) | Definiendo y liderando el edge (Nick McKeown Editorial) | del Día del Inversor Intel 2022 (Kit de prensa) Descargue una versión en PDF de este editorial
Pocas empresas están mejor equipadas para llevar al mundo a la próxima era de la IA: aprovechar nuestro amplio ecosistema, aprovechar el software abierto y, lo que es más importante, ofrecer una variedad de arquitecturas (desde CPU y GPU hasta ASIC y más) para atender a la gran cantidad de casos de uso de IA nos permitirá dar forma al mercado y allanar el camino para la IA abierta.
Una serie de arquitecturas infundidas con IA
Cuando se trata de IA, muchos saltan al entrenamiento de aprendizaje profundo y al rendimiento de la GPU. Las GPU reciben mucha atención porque el entrenamiento tiende a ser masivamente paralelo. Pero eso es solo una parte del panorama de la IA. Una gran parte de las soluciones prácticas de IA implican una combinación de algoritmos clásicos de aprendizaje automático y modelos de aprendizaje profundo de complejidad pequeña a mediana que están dentro de las capacidades de los diseños modernos de CPU como Xeon.
Hoy en día, la canalización de flujo de datos de IA se ejecuta principalmente en Xeon, y estamos haciendo que Xeon se ejecute aún más rápido con aceleración incorporada y software optimizado. Con Sapphire Rapids, nuestro objetivo es ofrecer una ganancia total de rendimiento de IA de hasta 30 veces con respecto a la generación anterior, y estamos haciendo que Xeon sea aún más competitivo al traer más cargas de trabajo de IA a Xeon para reducir la necesidad de aceleradores discretos. Para algunos productos de Intel, como Xeon, las capacidades y optimizaciones de IA no son un concepto nuevo, y planeamos expandir este enfoque, incorporando IA en cada producto que enviamos, ya sea en el centro de datos, el cliente, el edge o los gráficos.
Para la capacitación de aprendizaje profundo que realmente funciona mejor en las GPU, queremos que los clientes tengan la libertad de elegir la mejor computación para sus trabajos de IA. Las GPU de hoy en día son cerradas y propietarias, pero tenemos un procesador de IA específico del dominio en Habana Gaudí, y una GPU centrada en HPC en Ponte Vecchio que se basará en estándares abiertos de la industria. Estamos satisfechos con el progreso de Gaudí, con el anuncio de disponibilidad general de Amazon Web Services (AWS) en el cuarto trimestre de 2021 de que las instancias DL1 basadas en Habana Gaudi funcionan hasta un 40% mejor que las instancias existentes basadas en GPU en el rendimiento de precios, y con los primeros testimonios de experiencias de Gaudí.
Aprovechar un ecosistema establecido y captar más clientes
Los modelos, algoritmos y requisitos específicos cambian según el caso de uso y la industria. Por ejemplo, una empresa de vehículos autónomos necesita resolver problemas que abarcan la percepción (utilizando la detección, localización y clasificación de objetos), el mapeo de alta definición y la planificación de rutas con acciones que deben adaptarse a un entorno dinámico. Por otro lado, un chatbot para una aplicación de soporte técnico debe comprender la jerga técnica de la empresa y la industria en particular para responder preguntas de manera relevante. Las necesidades de hardware y software de IA también varían según el cliente, el segmento, la carga de trabajo y los puntos de diseño. La IA de dispositivos, integrada y cliente requiere sistemas de inferencia de baja latencia en envolventes térmicas y de potencia restringidas, y muchos, pero no todos, requieren asistencia con herramientas de código bajo o sin código. También existe una creciente demanda de que la IA desarrollada en la nube sea consciente del edge, de modo que las soluciones desarrolladas en la nube se puedan implementar en el edge (o viceversa).
Todos estos factores están impulsando la innovación en todos los ámbitos, desde el centro de datos hasta la red y desde el edge, e influyendo en la arquitectura de hardware a nivel del sistema, incluida la memoria de alto ancho de banda y alta capacidad, las interconexiones rápidas y el software inteligente.
{kind=link}
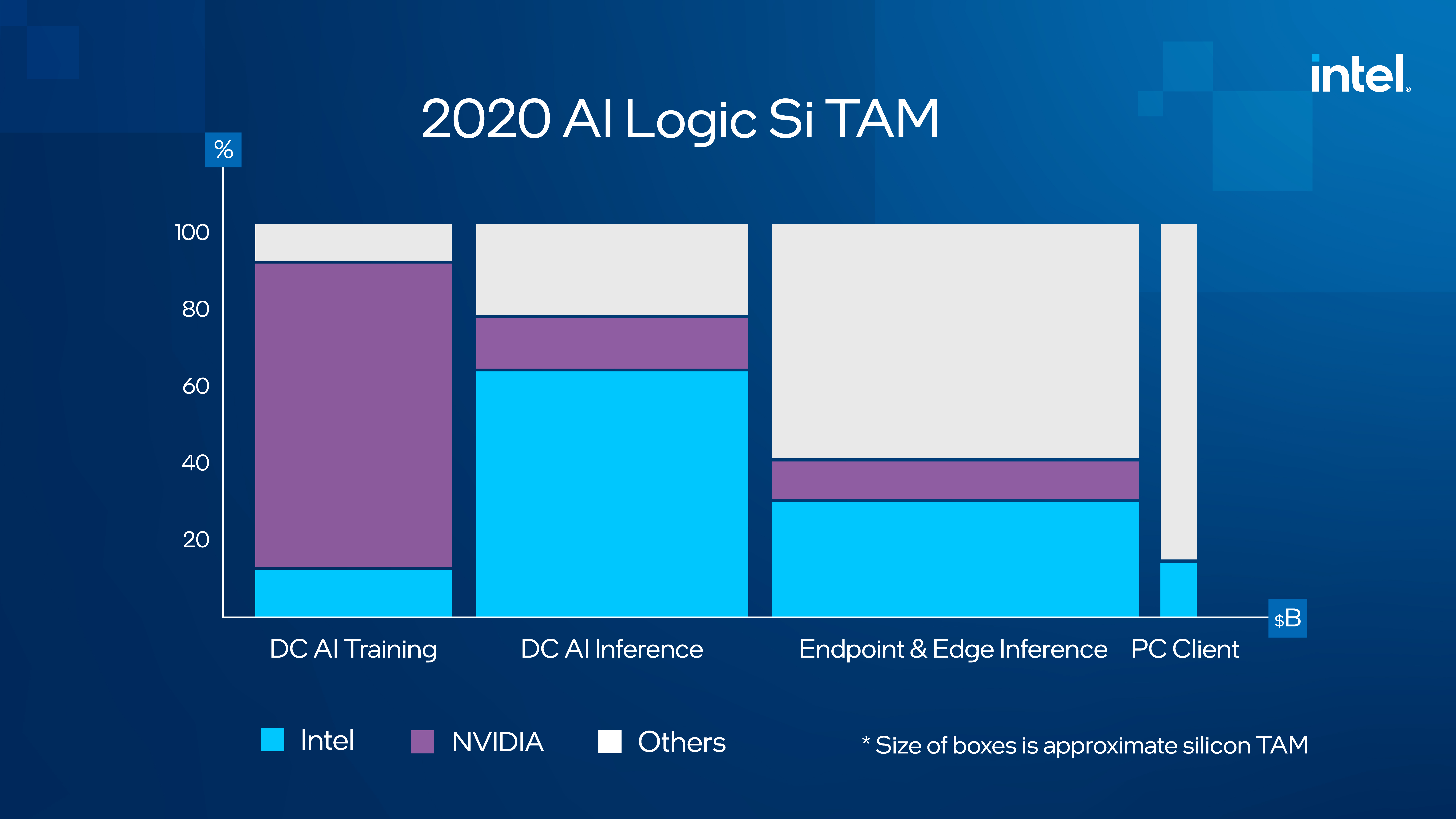
El mercado de mayor crecimiento dentro de la canalización de flujo de trabajo de IA de extremo a extremo se encuentra dentro de la fase de implementación de modelos e inferencia de IA. Hoy en día, más del 70% de la inferencia de IA se ejecuta en Xeon, y uno de los casos de uso de inferencia de IA de más rápido crecimiento es el edge inteligente, donde Xeon ha establecido un fuerte punto de apoyo.
He pasado los últimos ocho meses interactuando con clientes y aprendiendo más sobre sus necesidades y cargas de trabajo. Estas conversaciones nos han dado una idea de lo que algunos de los clientes más influyentes (como los proveedores de servicios en la nube) necesitan y nos han mostrado cómo las asociaciones estratégicas pueden ayudar a informar áreas clave de nuestra cartera. Hay decenas de miles de instancias en la nube que se ejecutan en Intel hoy en día, y está creciendo más rápido que cualquier otra arquitectura. Hay cientos de miles de millones de líneas de código escritas en x86 y cientos de millones de Xeons instalados en toda la industria. Intel está en una posición única para impulsar la industria horizontalmente con los estándares de la industria y verticalmente en segmentos como la automatización y la atención médica, donde las necesidades son más especializadas.
Una pirámide de software abierta para desarrolladores de IA
Nos damos cuenta de que el hardware es solo una parte de la solución, y estamos adoptando una mentalidad de software primero con nuestra estrategia de IA. El software incluye primero componentes de software de IA seguros que permiten a los usuarios aprovechar el software único y las características de seguridad de Xeon, como la informática confidencial a través de Intel® Software Guard Extension (Intel® SGX), que protege los datos y el software críticos mientras está en uso. Intel SGX es el primer y más implementado entorno de ejecución confiable basado en hardware de la industria para el centro de datos, y nuestra hoja de ruta Xeon incluye tecnologías informáticas más confidenciales que ampliarán nuestra posición de liderazgo.
Hemos pasado años optimizando los marcos y bibliotecas de código abierto más populares para nuestras CPU, y tenemos la cartera más amplia de aceleradores específicos de dominio que se basan en un estándar abierto para facilitar el uso del código y evitar el bloqueo, y sin embargo, tenemos más que hacer para aumentar nuestra posición y avanzar. Queremos habilitar una IA abierta que abarque desde la nube y el centro de datos hasta el cliente, el edge y más allá.
Si bien habilitar las optimizaciones de Intel en los marcos de IA de forma predeterminada es fundamental para impulsar una amplia adopción de silicio, debemos satisfacer las necesidades de todo tipo de desarrolladores de IA. Eso incluye a los desarrolladores de marcos que trabajan en la última capa de la lista de software para expertos en la materia de código bajo o sin código y todos los elementos de ingeniería y operativos de implementación, ejecución, capacitación y mantenimiento de modelos de IA (MLOps). Aunque sus roles son muy diferentes, cada etapa del flujo de trabajo de IA comparte deseos comunes: pasar del concepto a la escala del mundo real rápidamente, con el menor costo y riesgo. Esto significa opciones y soluciones abiertas basadas en marcos comunes que son fáciles de implementar y mantener.
Hemos creado BigDL, que admite el aprendizaje automático a gran escala en la infraestructura de big data existente, y OpenVino™, que acelera y simplifica la implementación de inferencias en muchos objetivos de hardware diferentes con cientos de modelos preentrenados. Sabemos que, con estándares y API consistentes, bloques de construcción componibles / optimizados para desarrolladores que trabajan en los niveles más bajos de la lista de IA, y herramientas y kits optimizados y productizados para desarrolladores de código bajo, los desarrolladores de IA prosperarán con Intel. Nuestras continuas inversiones en aceleradores de IA y seguridad nos permitirán hacer que estos elementos críticos de la computación estén presentes para todos nuestros clientes, segmentos de mercado y productos.
IA impulsada por Intel
La inteligencia artificial ya está transformando las industrias, y tiene el potencial de mejorar la vida de cada persona en la Tierra, pero solo si se puede implementar más fácilmente y a escala. Reducir la barrera de entrada para la IA requiere la colección correcta de tecnologías infundidas con IA. Nuestro enfoque es una fórmula ganadora que acelerará la próxima era de innovaciones de IA: al ayudar a definir el entorno de desarrollo a través de nuestros esfuerzos de código abierto, podremos desarrollar e influir en las soluciones de los clientes que afectan a industrias enteras. Pronosticamos que el TAM de silicio de lógica de IA de Intel será de más de $ 40 mil millones para 2026. Estamos abordando esta oportunidad desde una posición de fuerza, y estoy emocionado por lo que nos depara el futuro.
Sandra L. Rivera es vicepresidenta ejecutiva y gerente general del Grupo de Centros de Datos e IA de Intel Corporation.